.png)

Cloud spending has become one of the fastest-growing line items in modern tech organizations, and yet 25–35% of that spend is still wasted due to poor purchasing decisions, and inconsistent FinOps practices. As cloud environments scale and architectures become more distributed, the pressure on teams to optimize spend has never been greater. This is where the FinOps Build vs Buy dilemma emerges.
Should your team build a custom cloud optimization platform tailored to your internal workflows and governance needs? Or should you buy a purpose-built, automated FinOps solution that delivers immediate visibility, savings, and risk reduction?
In reality, “build” can mean anything from stitching together AWS Cost Explorer and custom automation, to developing a full internal optimization engine. “Buy” can range from lightweight reporting tools to fully autonomous platforms. The challenge is knowing which path actually produces the lowest operational burden, and the best long-term ROI for your team.
This guide breaks that decision down into the parts that matter most so you can choose the approach that delivers the most value for your FinOps maturity and cloud environment.
Today, cloud architectures are changing faster than most internal tools can support. Tasks like autoscaling workloads, ephemeral resources, containerized services, and emerging GPU/AI patterns create usage variability that forces teams to continuously recalculate pricing, commitments, and optimization strategies.
So, whether you build or buy a platform, it must keep up with frequent provider changes, new instance families, shifting discount models, and multi-cloud data fragmentation. This alone makes cloud optimization a moving target rather than a static engineering project.
At the same time, FinOps practices have matured too. Teams now depend on automated rightsizing, real-time commitment management, anomaly detection, and accurate allocation to drive financial accountability across engineering. These capabilities require reliable pipelines, precise data modeling, and decision engines that safely automate changes without introducing risk. Maintaining that level of accuracy and automation internally requires dedicated engineering capacity, often far more than teams anticipate.
Also read: Save 30-50% on AWS in Under 5 Minutes: The Complete Setup Guide
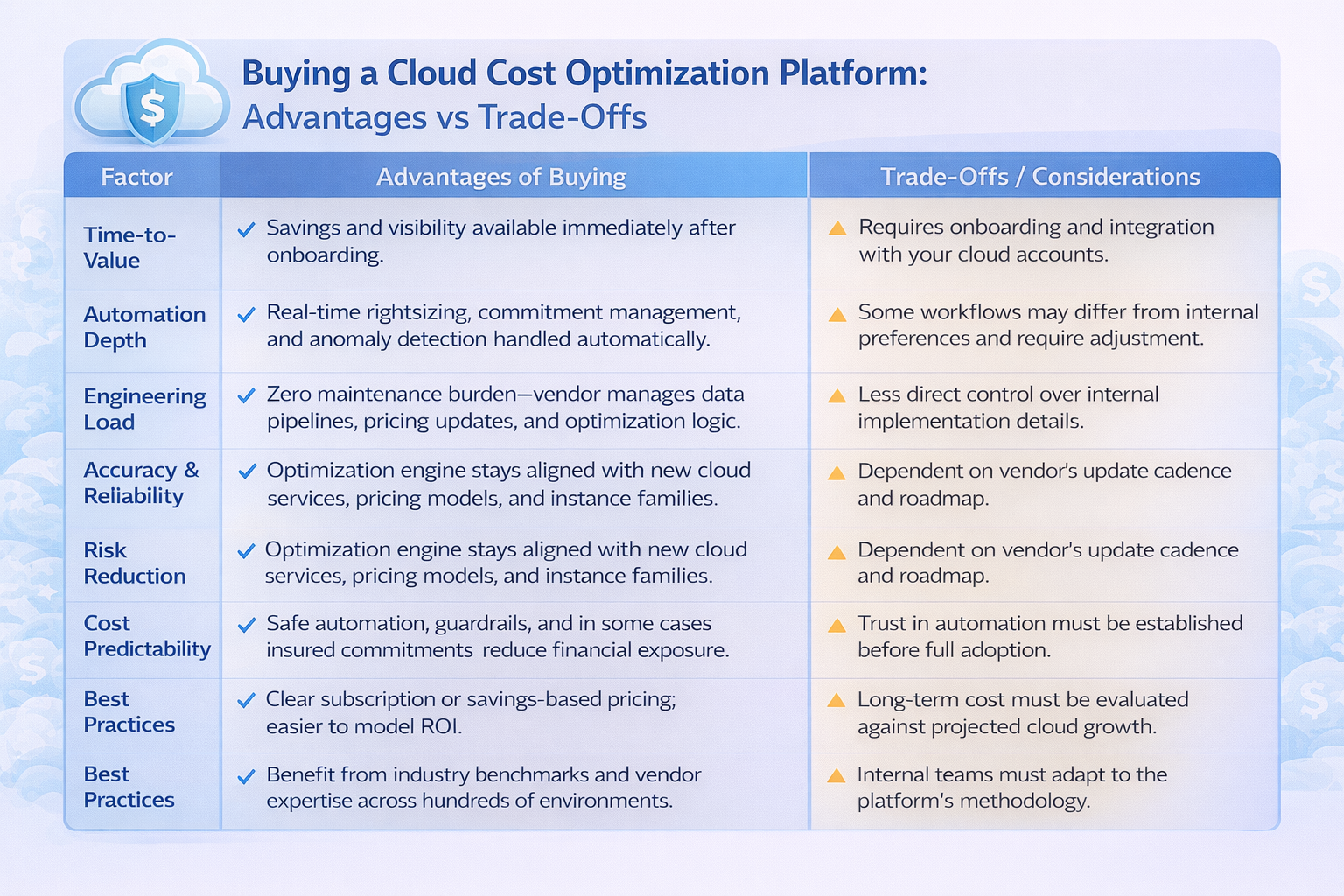
Building your own cloud cost optimization platform will give you full control over how data is ingested, normalized, modeled, and acted on. You can tailor allocation rules, commit modeling, governance workflows, and reporting structures to match your internal architecture and organizational policies. Moreso, if your team has unique workload patterns, nonstandard billing needs, or strict security boundaries, building can help you create an exact fit without depending on a vendor’s roadmap or release cycle.
However, building also means owning the engineering complexity that comes with cloud cost optimization. You’re responsible for maintaining data pipelines, updating pricing logic, validating recommendation accuracy, and ensuring your automation stays aligned with rapidly evolving cloud services. This includes keeping up with new instance families, changing discount instruments, dynamic Spot behavior, and multi-account spend patterns. The engineering time required to maintain correctness and reliability often grows faster than expected, especially once automation moves beyond basic reporting into proactive optimization.
If you have dedicated bandwidth, strong cloud economics expertise, and long-term appetite for maintaining an internal optimization engine, building can work. But if engineering constraints, time-to-value, or ongoing maintenance overhead are concerns, the build path quickly becomes a long-term operational commitment rather than a one-time project.

Buying a cloud optimization platform is less about convenience, and more about gaining access to capabilities that are extremely difficult, costly, or risky to operate internally. Modern optimization requires continuous data ingestion, automated decisioning, and safe execution. To get this done correctly means keeping hundreds of variables updated across compute families, pricing models, discount instruments, on-demand/spot markets, and region-by-region differences. Most engineering teams do not have the resources to maintain this reliably, let alone improve it over time.
A purpose-built optimization platform gives you an always-correct, always-current decision engine. It continuously updates pricing catalogs, monitors coverage drift, analyzes consumption patterns, simulates commitment exposure scenarios, and executes optimizations with rollback safety.
Another advantage of buying is risk reduction. Optimizing commitments manually or with basic scripts introduces two common failure modes:
Modern platforms solve this by analyzing volatility, and adjusting positions dynamically. Some tools even guarantee savings outcomes, an economic model no internal tool can replicate.
Finally, buying gives you predictable time-to-value. Instead of spending 6–18 months building a tool that still needs constant patching, you start generating measurable savings immediately.
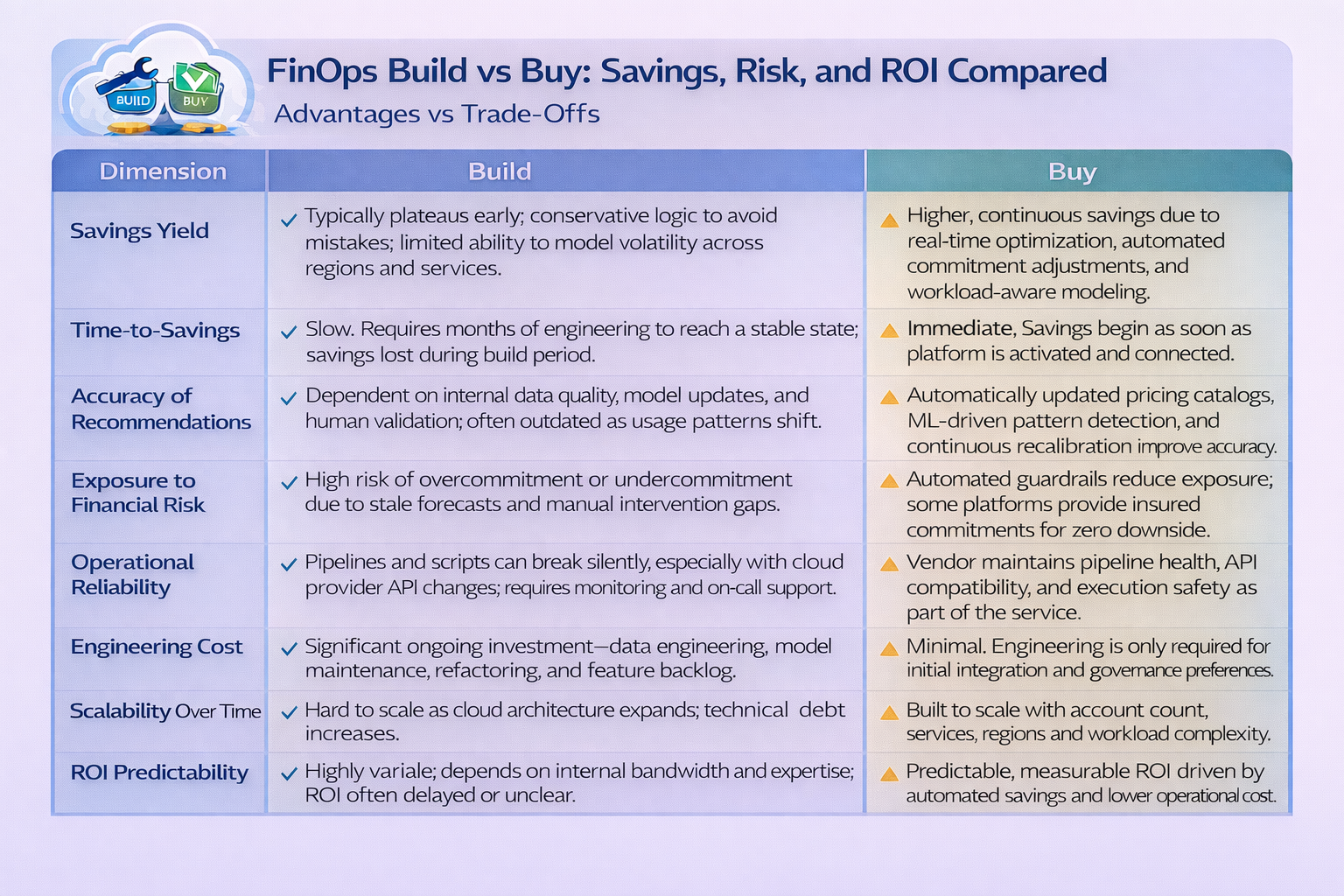
The Build vs Buy decision becomes clearer when you quantify the actual cost of owning a cloud optimization platform. Most teams compare subscription fees to “free internal engineering time,” but that comparison ignores the largest part of the equation, which is the ongoing cost of correctness.
Building an internal tool means you take responsibility for the entire lifecycle,right from data ingestion, normalization, anomaly detection, forecasting logic, commitment modeling, API updates, to safe execution. Each of these components has its own failure modes and maintenance cycles. What starts as a small project quickly becomes a long-term product that demands continuous engineering investment.
Buying a platform, on the other hand, concentrates the TCO into a predictable operating cost. You offload all your tasks like, pricing updates, forecasting models, decision logic, and execution frameworks to a vendor whose sole focus is keeping those systems accurate. Hence, the savings you rightfully captured minus the engineering hours you avoided is how you calculate the true ROI.
Also read: Cloud Cost Optimization: How to Cut Cloud Spend Without Taking Commitment Risk
When you compare Build vs Buy using real data instead of assumptions, the differences in savings and ROI become very obvious. Internal tools generally optimize slowly and conservatively, while purpose-built platforms optimize continuously and with higher accuracy. This gap compounds over time and directly affects your cloud efficiency.
A homegrown system typically starts with static rules, periodic analysis, and manual approvals. That model can’t account for the volatility in workload patterns, or changes in commitment instruments. As a result, the system either undercommits, leaving savings on the table or overcommits, introducing financial exposure. The average effective savings rate (ESR) from internal tools tends to plateau early because the recommendation logic does not evolve with your cloud usage.
Bought platforms operate as real-time optimization engines. They recalculate commitment positions continuously, measure workload stability, detect drift, identify anomalies, and adjust strategies automatically. This produces a materially higher savings yield and reduces the chance of miscommitment. Automation also removes the risk tied to human timing. You don’t miss savings because someone was on vacation, misread a coverage pattern, or paused a script that later failed silently.
ROI follows directly from these differences. A purchased platform begins generating savings immediately, while a built system takes months to reach a stable state. And because a vendor assumes the engineering cost of correctness, your team avoids the recurring expense of maintaining optimization models. The financial impact shows up as both higher realized savings and lower operational cost, creating a clearer and more predictable ROI curve.
Use the checklist below to score your environment and determine which option aligns with your FinOps maturity, engineering capacity, and savings goals.
1. Engineering Bandwidth
2. Time-to-Value Requirements
3. Optimization Complexity
4. Risk Tolerance
5. Data Quality & Pipeline Reliability
6. Governance & Transparency Needs
7. Long-Term TCO
8. Desired FinOps Maturity Level
Count the number of checkmarks on each side:
Usage AI is an autonomous cloud optimization platform that continuously analyzes your workloads, adjusts commitment positions safely, and protects you from financial exposure that internal tools are not designed to handle.
Unlike periodic scripts or dashboard-driven workflows, Usage AI runs as a real-time decision system. It ingests billions of data points, models workload volatility, and updates optimization strategies without requiring you to maintain pipelines, or custom automation logic. Instead of teaching your engineers cloud economics, Usage AI encodes it directly into the platform.
See how much you can save across AWS, Azure, and Google Cloud with Usage AI. Sign up now!
Share this post


.png)
.png)